「過去のデータの標準偏差」と「確率変数の標準偏差」
前回、平均には2種類あることを説明しました。全部たして標本数Nで割る「過去のデータの平均」と、確率を使って求める「確率変数の平均」の2つです。
同じように、標準偏差にも、「過去のデータの標準偏差」と、「確率変数の標準偏差」の2つがあります。過去のデータの標準偏差は「格差の指標」です。テストの点数に関するクラスの標準偏差であれば、クラス内にどれくらい点数のばらつきがあるかを教えてくれます。標準偏差が大きいということは、平均よりずっと点数が高い人も、ずっと低い人もたくさんいたということです。
一方の確率変数の標準偏差は、将来起こりうることのばらつきですから、格差というより「リスクの指標」です。明日の最高気温の標準偏差が大きいということは、予報よりもうんと高い値が出る可能性もあるし、うんと低い値が出る可能性も結構あり、とても不確実であることを意味します。
ただ、そういう意味を知ることも大事ですが、きちんと計算できることの方がもっと大事です。そこで、確率変数の標準偏差の計算法を学ぶために、前回のルーレットの例で、賞金額の標準偏差を求めてみましょう。計算には確率の情報を用います。確率分布は以下の通りです。
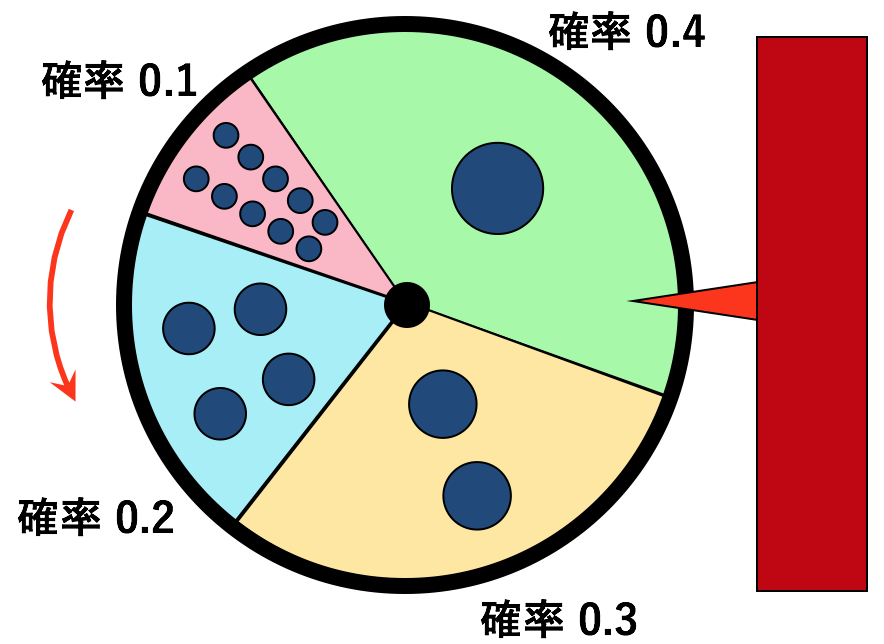
10万円(確率 0.1)
4万円(確率0.2)
2万円(確率0.3)
1万円(確率0.4)
標準偏差を計算する手順は、
手順1:平均を計算する
手順2:個々の値の「平均からのギャップ」を求める
手順3:「平均からのギャップ」をそれぞれ2乗した値の、平均を計算する
手順4:最後に平方根(ルート)を取る
となります。以前出てきた「過去のデータの標準偏差」の計算の手順と全く同じです。違うのは、手順1と3で平均を計算するときに確率を使うことだけです。手順1は10万、4万、2万、1万を、確率を使って平均します。前回もやりましたが、 万円でしたね。手順2で求めるのは、それぞれの値の「平均(2.8万円)からのギャップ」で、順番に
万円でしたね。手順2で求めるのは、それぞれの値の「平均(2.8万円)からのギャップ」で、順番に 万、
万、 万、
万、 万、
万、 万です。手順3は、これの2乗、すなわち
万です。手順3は、これの2乗、すなわち ,
,  ,
,  ,
,  を、確率を使って平均します。つまり
を、確率を使って平均します。つまり です。手順4はこれの平方根をとるだけですから、標準偏差は
です。手順4はこれの平方根をとるだけですから、標準偏差は 万円となります。結果にばらつきのあるルーレットゲームであるほど、この値が大きくなるのです。
万円となります。結果にばらつきのあるルーレットゲームであるほど、この値が大きくなるのです。
ちなみにですが、手順3までやって、手順4をやる前の中途の数字を「分散(ぶんさん)」と呼ぶので、後々のために名前を覚えてください。「分散」の平方根を取ると、「標準偏差」の完成です。
次は「2つの確率変数の相関係数」を勉強します。
>> 確率統計の入り口(5)2つの確率変数のあいだの相関係数